
皆さんこんにちは。いし(@ishilog2)です。
今回はPythonを用いて、tenki.jpからデータ取得したいと思います。
スクレイピングが禁止されているWEBページもあるのでお気を付けください。
スポンサーリンク
導入編
今回のコードではrequestsとBeautifulSoup、Pandasを使用します。
インストールしていない方はインストールして下さい。
pip install requests pip install beautifulsoup4 pip install pandas
実践
実施すること
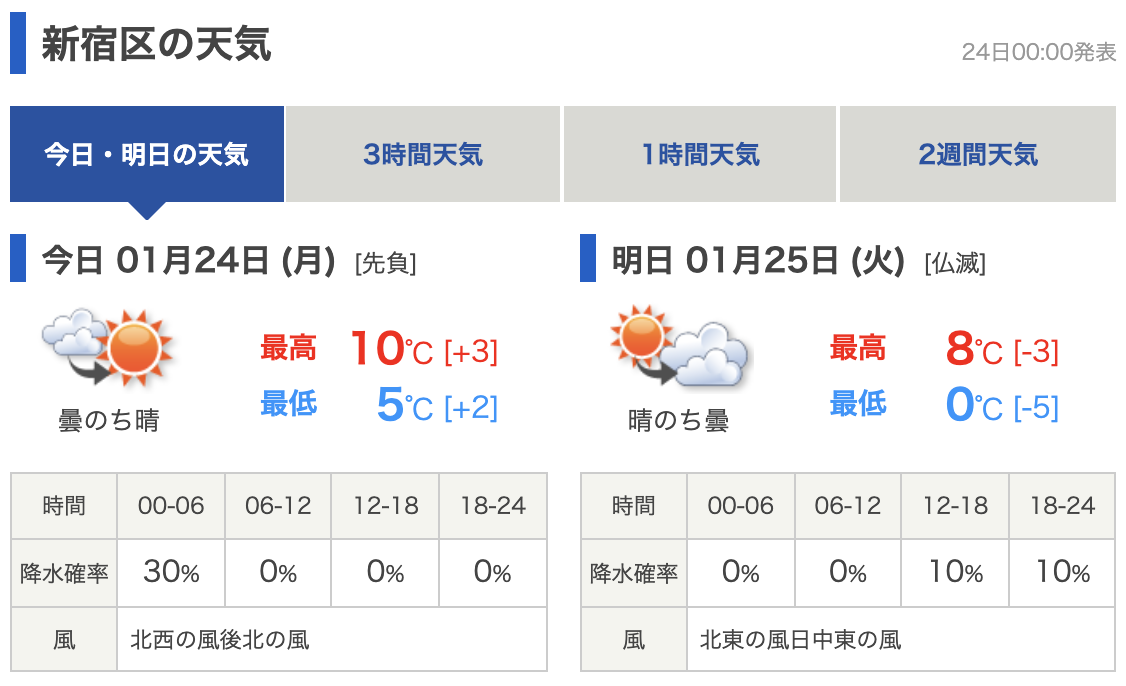
tenki.jpから本日の天気と明日の天気を取得します。
https://tenki.jp/forecast/3/16/4410/13104/
サンプルコード
import requests
from bs4 import BeautifulSoup
import pandas as pd
def GET_Weather():
url = "https://tenki.jp/forecast/3/16/4410/13112/"
r = requests.get(url)
soup = BeautifulSoup(r.text, "html.parser")
rs = soup.find(class_='forecast-days-wrap clearfix')
# 天気を取得
rs_wether = rs.findAll(class_='weather-telop')
today_weather = rs_wether[0].text.strip()
tomorrow_weather = rs_wether[1].text.strip()
# 最高気温を取得
rs_hightemp = rs.findAll(class_='high-temp temp')
today_hightemp = rs_hightemp[0].text.strip()
tomorrow_hightemp = rs_hightemp[1].text.strip()
# 最高気温差を取得
rs_hightempdiff = rs.findAll(class_='high-temp tempdiff')
today_hightempdiff = rs_hightempdiff[0].text.strip()
tomorrow_hightempdiff = rs_hightempdiff[1].text.strip()
# 最低気温を取得
rs_lowtemp = rs.findAll(class_='low-temp temp')
today_lowtemp = rs_lowtemp[0].text.strip()
tomorrow_lowtemp = rs_lowtemp[1].text.strip()
# 最高気温差を取得
rs_lowtempdiff = rs.findAll(class_='low-temp tempdiff')
today_lowtempdiff = rs_lowtempdiff[0].text.strip()
tomorrow_lowtempdiff = rs_lowtempdiff[1].text.strip()
# 降水確率を取得
rs_rain = soup.select('.rain-probability > td')
today_rain_1 = rs_rain[0].text.strip()
today_rain_2 = rs_rain[1].text.strip()
today_rain_3 = rs_rain[2].text.strip()
today_rain_4 = rs_rain[3].text.strip()
tomorrow_rain_1 = rs_rain[4].text.strip()
tomorrow_rain_2 = rs_rain[5].text.strip()
tomorrow_rain_3 = rs_rain[6].text.strip()
tomorrow_rain_4 = rs_rain[7].text.strip()
# 風向
rs_wind = soup.select('.wind-wave > td')
print(rs_wind)
today_wind = rs_wind[0].text.strip()
tomorrow_wind = rs_wind[1].text.strip()
# 取得結果をdfに格納
df = pd.DataFrame(
data={'#': ['天気', '最高気温', '最高気温差', '最低気温', '最低気温差',
'降水確率[00-06]', '降水確率[06-12]', '降水確率[12-18]',
'降水確率[18-24]', '風向'],
'今日': [today_weather, today_hightemp, today_hightempdiff,
today_lowtemp, today_lowtempdiff, today_rain_1, today_rain_2,
today_rain_3, today_rain_4, today_wind],
'明日': [tomorrow_weather, tomorrow_hightemp, tomorrow_hightempdiff,
tomorrow_lowtemp, tomorrow_lowtempdiff, tomorrow_rain_1, tomorrow_rain_2,
tomorrow_rain_3, tomorrow_rain_4, tomorrow_wind],
}
)
print(df)
GET_Weather()
結果
0 天気 晴一時雨 晴のち曇 1 最高気温 10℃ 8℃ 2 最高気温差 [+3] [-2] 3 最低気温 5℃ 0℃ 4 最低気温差 [+2] [-5] 5 降水確率[00-06] 50% 0% 6 降水確率[06-12] 0% 0% 7 降水確率[12-18] 0% 10% 8 降水確率[18-24] 0% 10% 9 風向 北の風 北東の風日中東の風
ABOUT ME
スポンサーリンク
スポンサーリンク










